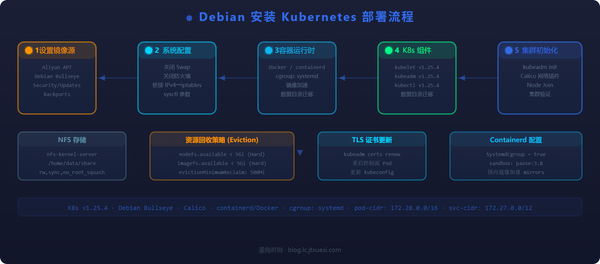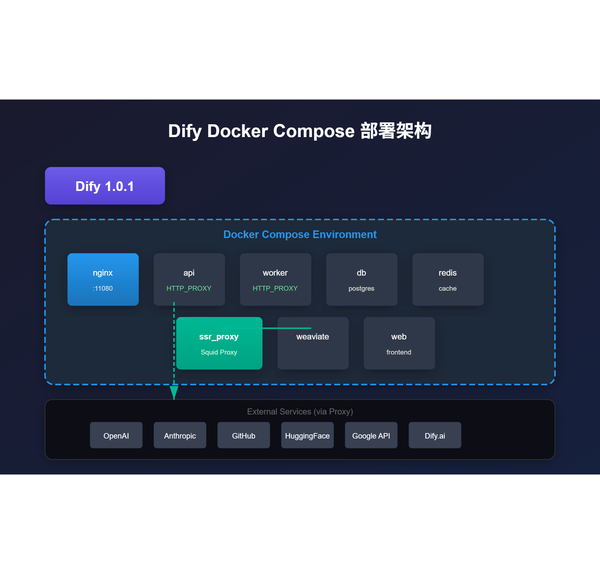
容器化
Dify 私有化部署全解析:构建企业级 AI 应用开发平台
前言 在人工智能快速发展的今天,如何快速构建和部署 AI 应用已成为企业数字化转型的核心挑战。Dify 作为一款开源的 LLMs(大型语言模型)应用开发平台,凭借其直观的设计和强大的功能,已帮助数万家企业实现了 AI 能力的快速落地。本文将深入解析基于 Docker 的 Dify 私有化部署方案,带你一步步构建属于自己的企业级 AI 应用开发平台。 一、项目概览 1.1 什么是 Dify? Dify 是一个开源的 LLMs 应用开发平台,支持超过数百种主流 AI 模型的接入,包括 GPT、Claude、Gemini、通义千问、文心一言等。其核心功能包括: * 可视化 AI 工作流编排:通过拖拽式界面,轻松构建复杂的 AI 工作流程 * RAG