Kubernetes 全栈监控体系:kube-prometheus-stack + 7 大 Exporter 生产实践
本文基于 kube-prometheus-stack Helm Chart 在 Kubernetes 上构建完整监控体系的实战,覆盖 Prometheus、Grafana、Alertmanager 及 7 个专用 Exporter 的部署与配置。
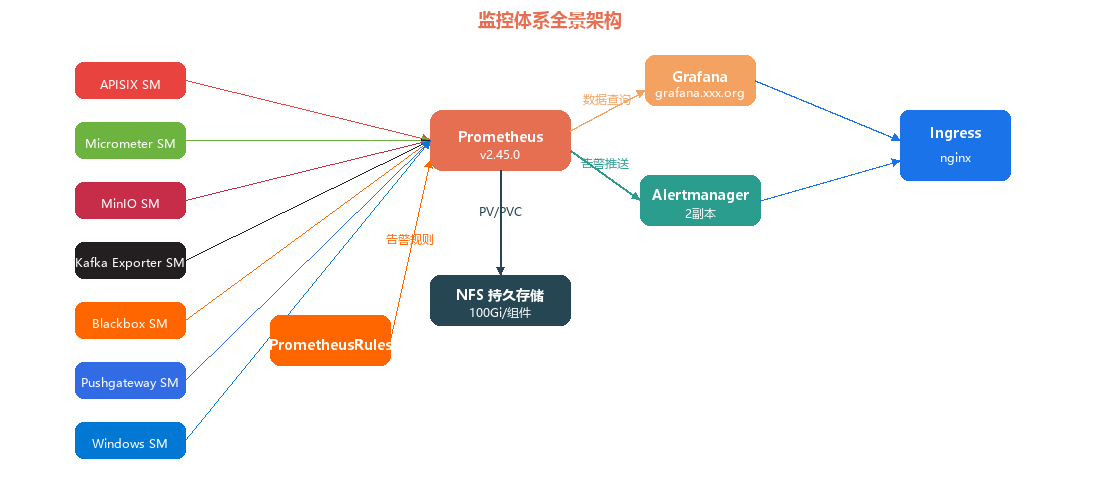
一、监控体系全景架构
整套监控以 kube-prometheus-stack 为核心,通过 ServiceMonitor CRD 自动发现并采集 7 大数据源,配合 Alertmanager 分级告警与 Grafana 可视化:
| 组件 | 版本 | 作用 |
|---|---|---|
| Prometheus | v2.45.0 | 指标采集与存储,10 天数据保留 |
| Alertmanager | v0.25.0 | 告警路由与邮件推送,2 副本 HA |
| Grafana | 11.1.1 | 可视化面板,Ingress 暴露 |
| Prometheus Operator | — | 管理 Prometheus/Alertmanager 生命周期 |
所有组件运行在 monitoring Namespace,通过 NFS 持久化存储保障数据安全。
二、NFS 持久化存储规划
Prometheus、Alertmanager、Grafana、Thanos 各组件均使用 NFS 作为持久存储,通过静态 PV + PVC 绑定:

| 组件 | PV 名称 | 容量 | StorageClass | 访问模式 |
|---|---|---|---|---|
| Prometheus | nfs-pv-prometheus-prometheus | 300Gi | nfs-prometheus-prometheus | ReadWriteMany |
| Alertmanager-0 | nfs-pv-prometheus-alertmanager | 300Gi | nfs-prometheus-alertmanager | ReadWriteMany |
| Alertmanager-1 | nfs-pv-prometheus-alertmanager-1 | 300Gi | nfs-prometheus-alertmanager | ReadWriteMany |
| Grafana | nfs-pv-prometheus-grafana | 300Gi | nfs-prometheus-grafana | ReadWriteMany |
| Thanos | nfs-pv-prometheus-thanos | 300Gi | nfs-prometheus-thanos | ReadWriteMany |
spec:
persistentVolumeReclaimPolicy: Retain
nfs:
server: <nfs-server-ip>
path: "/home/data/share/prometheus/prometheus/"
Retain回收策略确保 PV 删除后数据不丢失ReadWriteMany允许多 Pod 同时读写(Alertmanager 2 副本共享同 StorageClass 下不同 PV)
三、7 大 ServiceMonitor 采集源

3.1 APISIX 指标采集
跨 Namespace 采集 APISIX 网关指标,5 秒高频采集:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: prometheus-apisix
namespace: monitoring
labels:
release: kube-prometheus-stack
spec:
selector:
matchLabels:
app: apisix-metircs
namespaceSelector:
matchNames:
- "bjac-apisix"
endpoints:
- port: metircs
interval: 5s
path: /apisix/prometheus/metrics
3.2 Micrometer(Java 应用)指标采集
采集 Spring Boot 应用的 Micrometer 指标,跨环境选择:
spec:
selector:
matchExpressions:
- { key: app, operator: In, values: [micrometer-doc-api-test-metircs, micrometer-doc-api-metircs] }
- { key: environment, operator: NotIn, values: [dev] }
namespaceSelector:
matchNames:
- "bjac-case"
endpoints:
- port: metrics
interval: 15s
path: /actuator/prometheus
metricRelabelings:
- sourceLabels: [instance]
targetLabel: ipport
- sourceLabels: [pod]
targetLabel: instance
关键设计:matchExpressions 排除 dev 环境,metricRelabelings 将 pod 标签替换 instance,便于 Grafana 按实例筛选。
3.3 MinIO 指标采集
MinIO 需要 Bearer Token 认证才能访问指标端点:
endpoints:
- port: metrics
interval: 30s
path: /minio/v2/metrics/cluster
bearerTokenSecret:
key: bearer_token
name: minio-bjac-bearer-token
同时采集 bucket 级别指标(/minio/v2/metrics/bucket),通过独立 ServiceMonitor 实现。
3.4 Kafka Exporter
通过 hostAliases 解决 Kafka 集群 DNS 解析:
kafkaServer:
- kafka01:9092
- kafka02:9092
- kafka03:9092
hostAliases:
- ip: "xxx.xxx.xxx.xxx"
hostnames:
- "kafka01"
ServiceMonitor 10 秒采集间隔,additionalLabels.release: kube-prometheus-stack 确保 Prometheus Operator 自动发现。
3.5 Blackbox Exporter
黑盒探测 HTTP 可用性与 SSL 证书状态,自定义探测模块:
config:
modules:
http_2xx_reg_doc4j:
prober: http
timeout: 5s
http:
valid_status_codes: [200, 301, 302]
fail_if_body_not_matches_regexp:
- "<operational>true</operational>"
此模块不仅检查 HTTP 状态码,还验证响应体内容是否包含 <operational>true</operational>,确保业务真正可用。
3.6 Pushgateway
接收短生命周期任务的推送指标,Ingress 暴露 pushgateway.xxx.org:
persistentVolume:
enabled: true
storageClass: "minio-storage"
size: 2Gi
serviceMonitor:
honorLabels: true
honorLabels: true 保留推送端原始 job/instance 标签,避免与 Pushgateway 自身标签冲突。
3.7 Windows Exporter(外部服务发现)
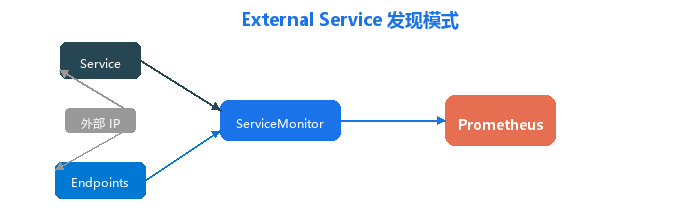
Windows 节点不在 Kubernetes 集群内,采用 Service + Endpoints 手动注册模式:
apiVersion: v1
kind: Service
metadata:
name: external-service-windows-exporter
namespace: monitoring
spec:
ports:
- port: 9182
targetPort: 9182
name: metrics
---
apiVersion: v1
kind: Endpoints
metadata:
name: external-service-windows-exporter
subsets:
- addresses:
- ip: xxx.xxx.xxx.xxx
nodeName: doc4j-183
- ip: xxx.xxx.xxx.xxx
nodeName: doc4j-184
ports:
- name: metrics
port: 9182
Service 与 Endpoints 同名绑定,Prometheus 通过 ServiceMonitor 发现该 Service,进而从 Endpoints 指定的外部 IP 采集指标。
同样模式也用于采集集群外的 MinIO Converter 实例。
四、告警体系
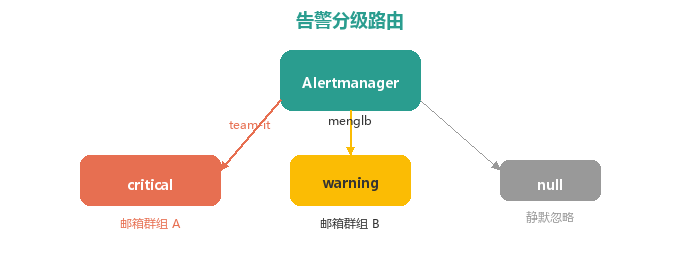
4.1 Alertmanager 分级路由
route:
group_by: ['namespace', 'alertname', 'cluster']
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
routes:
- matchers:
- severity =~ "warning|info"
receiver: 'menglb'
- matchers:
- severity =~ "critical"
receiver: 'team-it'
| 级别 | 接收者 | 说明 |
|---|---|---|
| critical | team-it 邗组 | 紧急问题,全员通知 |
| warning | menglb 个人 | 预警提醒,单人关注 |
| InfoInhibitor/Watchdog | null | 静默忽略,抑制低级告警 |
抑制规则确保同一 namespace + alertname 下,critical 告警自动抑制 warning/info。
4.2 Blackbox 探测告警

| 规则 | 表达式 | 级别 | 说明 |
|---|---|---|---|
| 接口宕机 | probe_success == 0 |
critical | 立即告警,零容忍 |
| HTTP 异常状态码 | status <= 199 或 >= 400 |
critical | 非 2xx/3xx 即异常 |
| 探测超时 | avg duration > 1s (5m) |
warning | 持续慢响应 |
| SSL 证书即将过期 | cert expiry < 30d |
warning | 30 天预警 |
| SSL 证书已过期 | cert expiry <= 0 |
critical | 证书失效 |
4.3 Kafka 告警规则

| 规则 | 表达式 | 级别 |
|---|---|---|
| Broker 宕机 | kafka_brokers < 3 |
critical |
| 副本不足 | in_sync_replica < 3 |
critical |
| 消费延迟 | consumer_lag > 50 |
critical |
| 消费者数不足 | members < 15 |
critical |
4.4 MinIO 告警规则
| 规则 | 表达式 | 级别 |
|---|---|---|
| 节点离线 | nodes_offline > 0 (5m) |
warn |
| 磁盘离线 | disk_offline > 0 (5m) |
warn |
4.5 Micrometer 自定义告警
- alert: kafka客户端发送消息失败
expr: kafka_producer_success > 0
for: 0m
labels:
severity: critical
业务级告警,零容忍 —— 任何 Kafka 生产失败立即触发。
五、关键配置详解
5.1 Prometheus 存储
prometheusSpec:
retention: 10d
walCompression: true
replicas: 1
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: nfs-prometheus-prometheus
accessModes: ["ReadWriteMany"]
resources:
requests:
storage: 100Gi
- 10 天数据保留,平衡存储成本与排查需求
- WAL 压缩减少磁盘 I/O
- 单副本部署,NFS 存储保障数据持久
5.2 Alertmanager 高可用
alertmanagerSpec:
replicas: 2
retention: 120h
storage:
volumeClaimTemplate:
spec:
storageClassName: nfs-prometheus-alertmanager
resources:
requests:
storage: 100Gi
2 副本确保告警不丢失,120 小时告警历史保留。
5.3 Grafana 配置
grafana:
adminPassword: <grafana-password>
persistence:
enabled: true
storageClassName: nfs-prometheus-grafana
size: 100Gi
ingress:
enabled: true
ingressClassName: nginx
hosts:
- grafana.xxx.org
sidecar:
dashboards:
searchNamespace: ALL
datasources:
defaultDatasourceEnabled: true
- Ingress 暴露
grafana.xxx.org - sidecar 自动发现所有 Namespace 的 Dashboard ConfigMap
- 默认数据源自动指向 Prometheus
5.4 Windows 监控启用
windowsMonitoring:
enabled: true
job: prometheus-windows-exporter
kube-prometheus-stack 开箱支持 Windows 监控,自动部署 Windows Dashboard 和告警规则。
5.5 节点调度
nodeSelector:
flink-server: "true" # Prometheus/Alertmanager/Thanos
kubernetes.io/hostname: stream-node-03 # Grafana
Prometheus 组件调度到计算节点,Grafana 固定到特定节点。
5.6 iptables 安全加固
iptables -I INPUT -p tcp --dport 9100 -j DROP
iptables -I INPUT -s xxx.xxx.xxx.0/24 -p tcp --dport 9100 -j ACCEPT
iptables -I INPUT -s xxx.xxx.xxx.xxx -p tcp --dport 9100 -j ACCEPT
限制 node-exporter 9100 端口仅允许内网访问,防止指标泄露。
六、部署流程

步骤 1:创建 Namespace
kubectl create ns monitoring
步骤 2:拉取镜像并推送到私有仓库
部分镜像(如 webhook-certgen)需从 registry.k8s.io 拉取后推送至私有仓库:
docker pull registry.k8s.io/ingress-nginx/kube-webhook-certgen:<tag>
docker tag <image> <private-registry>/tools/<image-name>:<tag>
docker push <private-registry>/tools/<image-name>:<tag>
步骤 3:配置 NFS PV
kubectl apply -f nfs-pv.yaml
步骤 4:Helm 部署 kube-prometheus-stack
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm pull prometheus-community/kube-prometheus-stack --untar
cd /home/helm/kube-prometheus-stack
helm install kube-prometheus-stack . --namespace monitoring
步骤 5:部署各 Exporter
# Blackbox
helm install prometheus-blackbox-exporter . --namespace monitoring
# Kafka Exporter
helm install prometheus-kafka-exporter . --namespace monitoring
# Pushgateway
helm install prometheus-pushgateway-bjac . --namespace monitoring
步骤 6:配置告警规则与 ServiceMonitor
# APISIX
kubectl apply -f apisix/servicemonitor.yaml
# Micrometer
kubectl apply -f micrometer/servicemonitor.yaml
kubectl apply -f micrometer/prometheusrule.yaml
# MinIO
kubectl apply -f minio/servicemonitor.yaml
kubectl apply -f minio/servicemonitor-converter.yaml
kubectl apply -f minio/prometheusrule.yaml
# Kafka 告警
kubectl apply -f prometheus-kafka-exporter/prometheusrule.yaml
# Windows Exporter
kubectl apply -f containerd-windows-exporter/servicemonitor.yaml
七、实践总结
| 要点 | 说明 | 核心收益 |
|---|---|---|
| kube-prometheus-stack 一键部署 | Helm Chart 统一编排 | 减少运维复杂度 |
| NFS 持久存储 | 静态 PV + ReadWriteMany | 数据安全,多副本共享 |
| Alertmanager 2 副本 | HA 部署 | 告警零丢失 |
| 告警分级路由 | critical → team-it, warning → menglb | 精准通知,避免告警疲劳 |
| 告警抑制 | critical 抑制同 namespace warning | 减少重复告警 |
| 7 大 ServiceMonitor | K8s 内 + 外部全覆盖 | 全栈可观测 |
| External Service 模式 | Service + Endpoints 手动注册 | 无需改造 Windows/外部节点 |
| Bearer Token 认证 | MinIO 指标端点认证 | 安全采集 |
| Micrometer 标签重写 | pod → instance | Grafana 实例筛选友好 |
| Windows 监控 | containerd + windows-exporter | 混合集群全覆盖 |
| iptables 端口限制 | node-exporter 9100 仅内网访问 | 指标安全 |
| Ingress 统一暴露 | grafana/alertmanager/pushgateway | 域名化访问 |



